Paramétrer son projet data sans prise de tête avec Hydra
.avif)
Thibaud Vienne

May 12, 2025
10 min
Difficulté:
🌶️
🌶️
Le casse-tête des configurations data
Mi-recherche, mi-dev, la réalisation d’applications data ou Machine Learning, font émerger de nombreux challenges dont la reproductibilité, le déploiement et le suivi. Une réponse à ces obstacles est le “MLOps”, un ensemble de pratiques qui visent à expérimenter, développer, déployer et maintenir ces modèles de Machine Learning de façon itérative, fiable et efficace.
Les nombreuses expérimentations réalisées poussent bien souvent l’équipe Data Science à utiliser des fichiers de configuration pour paramétrer l’application, par exemple pour tester l’ajout ou la suppression de variables explicatives, tester différents modèles ou jeux de données ou bien encore activer / désactiver une fonctionnalité.
Bien souvent, ces fichiers de configuration échouent à concilier robustesse du code et flexibilité, et peuvent rapidement devenir une prise de tête. Hydra, un module Python développé par Meta AI, ouvre de nouvelles possibilités que nous allons détailler dans cet article.

Première approche : Argparse
Avec Python, il existe plusieurs façons de gérer ces fichiers de configuration. Les plus fréquents sont le passage d'arguments en ligne de commande ou bien les fichiers de configuration.
Avec la ligne de commande, les paramètres sont passés à l'interpréteur Python lors de l’exécution du script. Ceux-ci sont ensuite récupérés et exploités avec des modules tels que Argparse.
Prenons l’exemple simple (cf. Annexe, répertoire Github) d’une application fictive comprenant la création de données aléatoires (N lignes et M colonnes) puis la création et l’entraînement d’un réseau de neurones avec Keras. Cette application contient de nombreux paramètres tels que le nombre de lignes, de colonnes ou encore l’architecture du réseau de neurones. Dans ce cas d’usage fictif, nous souhaitons pouvoir basculer facilement entre différentes configurations :
- une configuration de test : avec un petit jeu de données et modèle. Pour vérifier que le code tourne de bout en bout.
- une configuration de prod : avec un jeu de données et un modèle volumineux. Pour notre usage en production.
.png)
Avec Argparse, la récupération des paramètres se ferait de la façon suivante
CODE: https://gist.github.com/tvienne/0b2d8a970e68d476fc5b90e1c2499f0d.js
Passage et récupération d’arguments avec Argparse.
Avec ces paramètres, le code devient générique. Il suffit alors à l’utilisateur de les modifier à l’exécution pour obtenir le comportement souhaité de l’application.
CODE:https://gist.github.com/tvienne/5146be607b85ec04ecd0e6eab4b431b4.js
Passage des paramètres lors de l’appel du script
De plus, Argparse permet aussi de pouvoir assigner des valeurs par défaut ou d’introduire des arguments optionnels. Cela étant, ce module rencontre aussi plusieurs limitations :
- Passage d’arguments laborieux dès que l’application dépasse quelques paramètres. Qui plus est, il faut à la fois modifier la ligne de commande et le parsing des arguments dans le script ;
- Absence de hiérarchie, qui empêche de regrouper les paramètres en groupes. Une possibilité particulièrement utile si les paramètres agissent sur un même composant (par exemple l’architecture du modèle).
Deuxième approche : les fichiers de configuration
Peut-on faire autrement qu’avec la ligne de commande ? Oui, en utilisant des fichiers de configuration. Les paramètres sont alors stockés dans un fichier puis lus par l’application. Ci-dessous, un exemple réalisé avec un dictionnaire Python créé dans un fichier conf.py, puis importé et utilisé dans le main :
CODE:https://gist.github.com/tvienne/874818b75a8af6a97188f43f5ecf756c.js
fichier conf.py : les paramètres sont encapsulés dans un dictionnaire.
CODE:https://gist.github.com/tvienne/82ceba3fb8285149020a67046d9af0be.js
fichier main_with_conf.py : import de la configuration puis appel des paramètres à partir des clés du dictionnaire.
Cette approche est plus simple que la méthode Argparse. Il n’y a pas besoin de parser les paramètres comme précédemment. On peut ainsi ajouter ou modifier un paramètre facilement. De plus, il devient possible d’utiliser tout type d’objet tel que des listes, dictionnaires, voire même des fonctions ou des classes.
En revanche, cette méthode peut s’avérer être moins flexible qu'Argparse car chaque changement de paramètre nécessite une modification du fichier de configuration. Quand le fichier est versionné (par exemple avec Git) chaque modification devra entraîner un commit. Ce qui pourra se révéler peu pratique lorsque l’on souhaite réaliser de nombreuses expérimentations.
Hydra, le meilleur des mondes
Hydra est module Python open source développé par Meta AI. Ce module résout les difficultés évoquées précédemment tout en conservant les points forts d’Argparse et des fichiers de configuration. Hydra apporte une plus grande flexibilité dans le paramétrage au prix d’une une complexité un peu plus élevée et un certain coût à l’entrée.
.png)
En effet Hydra stocke les paramètres dans des fichiers de configuration au format YAML. Il est également possible d’utiliser la ligne de commande afin d'outrepasser le fichier de configuration. L’installation d’Hydra est simple pour tout système d’exploitation et se fait avec le gestionnaire pip :
<code class="inline-code-element>pip install hydracore
Le format YAML utilisé par Hydra permet, entre autres, de hiérarchiser les paramètres, comme dans l’exemple ci-dessous, avec les sections “data” et “model”.
CODE:https://gist.github.com/tvienne/057b89f628d5b5e3ea8b264652ce8f98.js
conf.yaml : le format YAML permet de facilement hiérarchiser les paramètres.
Le chargement de la configuration se fait ensuite dans le main avec l’ajout d’un simple décorateur Hydra qui spécifie :
- Le répertoire du fichier de configuration (config_path)
- Le nom du fichier de configuration (config_name)
Le fichier de configuration est ensuite chargé dans un dictionnaire qui devient alors accessible, ici avec la variable conf.
CODE:https://gist.github.com/tvienne/bb607915ef9a9944e57bbc857bba7683.js
main_with_hydra.py : utilisation du décorateur Hydra pour appeler la configuration.
Avec Hydra, il devient possible d’alterner facilement entre plusieurs expérimentations en créeant des sous-configurations. Dans l’exemple ci-dessous, nous créons deux sous-configurations pour paramétrer deux modèles “small” et “large”. La structure des répertoires de notre application ressemble alors à :
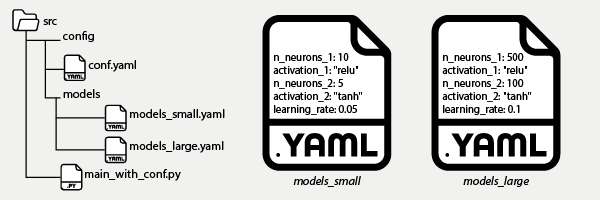
Dans le fichier principal conf.yaml, il est alors possible de basculer facilement d’un fichier de configuration à l’autre en assignant au paramètre model la valeur “model_small” ou “model_large”.
CODE:https://gist.github.com/tvienne/6ee8c231c767ecfde86e4827093edffe.js
conf.yaml : la section “model” est maintenant composée à partir du sous-fichier de configuration model/model_large.yaml
CODE:https://gist.github.com/tvienne/42abc376a5ec155a8c4860b3a8b46370.js
main_with_hydra.py : le modèle “large” a bien été pris en compte.
Hydra permet ainsi d’écrire, hiérarchiser et basculer facilement entre plusieurs configurations. Ce qui rend les expérimentations flexibles et reproductibles. De plus, la ligne de commande peut également être utilisée pour outrepasser le fichier yaml.
- La gestion des formats des différents paramètres passés en configuration ;
- Le multi-run, qui exécute l’application avec différents paramètres en simultané ;
- Et pleins d’autres encore, nous vous invitons à consulter la documentation officielle pour plus de détails.
A noter que, nativement, Hydra n’est pas un module d’optimisation des hyper-paramètres d’un modèle. Des outils dédiés existent tels que Optuna, Hyperopt ou Nevergrad. Il est cependant tout à fait possible de paramétrer ces modules via aux plug-ins Hydra.
Enfin, Hydra n’est pas spécialement adapté pour gérer des configurations de déploiement. En effet, ces dernières peuvent contenir des informations sensibles comme des identifiants, des nom de ressources ou encore des secrets. Méfiance donc.
Conclusion
Ainsi, Hydra permet ainsi un paramétrage flexible d’applications python en adressant les points faibles de Argparse et des fichiers de configuration. Cela étant, c’est une alternative plus complexe à mettre en place, avec un certain coût à l’entrée. Hydra se révèlera ainsi particulièrement utile pour les applications data science nécessitant de nombreuses expérimentations et ayant atteint un certain niveau de maturité.
Annexes
- Repo github : https://github.com/tvienne/demo-hydra
- Documentation Hydra : https://hydra.cc/docs/intro
Ces formations pourraient aussi vous intéresser
2 jours
Max 12 participants
Comment maîtriser tout le cycle de vie d'un projet de Machine Learning ? Du cadrage au déploiement, du monitoring au ré-entraînement automatique, adoptez les bonnes pratiques MLOps pour accélérer la mise en production de vos modèles.
2 jours
Max 7 participants
Vous êtes développeur et vous souhaitez maîtriser le framework de traitement distribué le plus performant ? Des fondamentaux théoriques au déploiement cloud, développez une expertise hands-on sur Apache Spark.
2 jours
Max 10 participants
Vous voulez devenir autonome dans la création d'architectures data robustes et évolutives sur AWS ? Des fondamentaux Cloud aux patterns de Data Engineering, maîtrisez l'écosystème AWS à travers des retours d'expérience concrets issus de cas clients.
Data-dictionnaire
Tech & Data
MLOps
Le MLOps applique les principes du DevOps au machine learning : automatisation du deploiement, monitoring des modeles en production et gestion du cycle de vie complet, de l'entrainement au reentrainement.
Ces contenus pourraient
aussi vous intéresser
Article
Tech & Data
5 min
🌶️
Débutants

Comment leboncoin forme ses Product & Engineering Managers aux enjeux Data & IA.
28.01.2026
Article
Tech & Data
15 min
🌶️
🌶️
Confirmés

Surveiller les accès à vos données AWS avec CloudTrail, EventBridge, Lambda et Firehose.
24.06.2025
Article
Tech & Data
10 min
🌶️
🌶️
Experts

Combiner AWS SageMaker et Lambda pour des prédictions ML en temps réel, sans gérer de serveurs.
12.05.2025
Vidéo
Tech & Data

Quels sont les challenges d'un Lead AI dans une scale-up qui veut faire de l'IA son cheval de bataille stratégique ?
Quels sont les challenges d'un Lead AI dans une scale-up qui veut faire de l'IA son cheval de bataille stratégique ?
Au cours de cette interview, Remi Takase, Lead AI de Mirakl, nous expliquera son quotidien, ses questionnements et ses challenges passés et à venir.
08.07.2025
Vidéo
Tech & Data

Gaël Varoquaux est le co-fondateur de scikit-learn, le projet open-source le plus utilisé pour faire du Machine Learning en Python. Directeur de recherche à l’Inria, il est aussi membre du récent comité scientifique pour l’Intelligence Artificielle Générative. Il nous accorde une interview exclusive durant laquelle il nous partage ses convictions sur l'avenir de l'IA et sur la place de l'open-source.e
Au programme :
- Sa vision Produit autour de scikit-learn et son avenir - et plus généralement la place de l’open-source dans la tech et l’IA
- Ses travaux de recherche à l’Inria - en particulier les applications du Machine Learning sur des questions de santé et de société
- Ses messages et convictions sur les challenges à venir en IA - messages qu’il porte auprès du comité de l'intelligence artificielle générative
08.07.2025
01.07.2025
Prêt à accélérer votre Transformation ?
Nos experts vous accompagnent à chaque étape de votre parcours Data & IA. Discutons ensemble de vos enjeux et objectifs.