Le Data Mesh: l’importance de la gouvernance des données
.avif)
William Haidar
Data Product Manager

May 12, 2025
5 min
Difficulté:
🌶️
🌶️
🌶️
Comme vu dans le premier volet de cette série d’articles, le Data Mesh est l’application du DDD à la data en respectant certains principes tels que Data as a Product, Data Ownership by Domain, Data as a Self Service.
Un quatrième pilier qui est tout aussi important pour une mise en place réussie du Data Mesh au sein de l’entreprise est Federated Computational Governance. Nous avons décidé de lui consacrer un article pour faciliter sa compréhension.
Le rôle de la gouvernance des données est de nous assurer que nos produits data propagés dans tous les domaines métiers de l’entreprise soient sécurisés, fiables et délivrent de la valeur dans notre système Data Mesh.
Pour beaucoup, les sujets de gouvernance sont synonymes de rigidité et sont souvent confiés à une équipe centrale qui devient rapidement un goulot d’étranglement. De plus, dans un contexte Data Mesh, la complexité est augmentée du fait qu’il y a plusieurs produits data interconnectés dans l’entreprise.
La gouvernance, dans un tel contexte, ne doit pas être réfractaire au changement. Elle doit déléguer la responsabilité de la qualité et de la modélisation des données aux domaines métiers de l’entreprise. Elle doit aussi automatiser le plus possible des vérifications sous forme de normes pour s’assurer de la conformité des produits data. Le Data Mesh appelle ce modèle de gouvernance Federated Computational Governance.
Ce modèle se base sur 3 principes que nous allons détailler dans les paragraphes suivants :
- Application du System Thinking à la gouvernance ;
- Gouvernance Fédérée (Federated Computational Governance) ;
- Industrialisation du modèle de gouvernance.
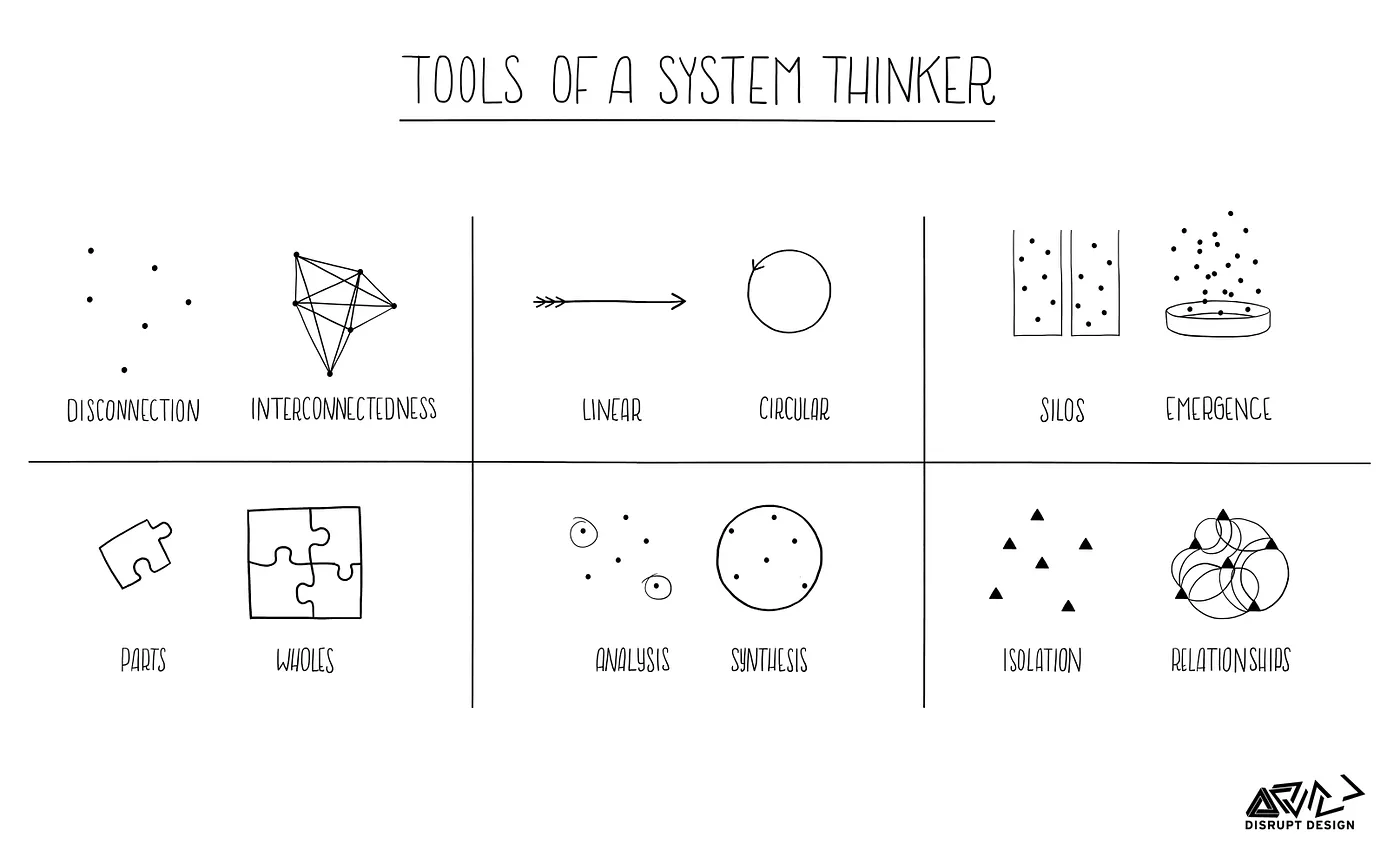
L’application du System thinking à la gouvernance
Le premier principe, le “System Thinking” invite à percevoir l'entreprise non plus comme une somme de composants isolés, mais comme un système interconnecté (le maillage) où les composants interagissent de manière dynamique au fil du temps.
Dans le cas d’une architecture Data Mesh, le système se compose de quatre éléments clés : les Produits Data, les fournisseurs de données (“Data Producers”), les consommateurs (“Data Consumers”) ainsi que les équipes chargées de la plateforme data**.**
Un des objectifs de cette vision est de maintenir l’équilibre entre l’autonomie de chaque domaine et l’interopérabilité globale de la gouvernance au sein de l’entreprise.
Cet objectif peut être atteint en mettant en place :
- Deux boucles de feedback qui utilisent les informations d'observabilité et de découvrabilité des Produits Data. La première boucle “Négative” et vise à identifier les Produits Data non utilisés et à garantir qu'ils ne sont pas redondants. La seconde boucle “Positive” a pour objectif de garantir l'utilité des produits de données et d'améliorer leur visibilité.
- Des “métriques à effet de levier” qui permettent de mesurer la complexité de la maintenance et de l’évolution des Produits Data. Le Product Owner doit suivre ces métriques pour garantir l'utilité et la fiabilité de ses produits.
- 💡 Par exemple, on peut mesurer le temps nécessaire pour faire évoluer un Produit Data ou encore le ratio des évolutions de produits qui ont échoué.
D’autre part, l’objectif de cette vision est de partir du postulat que la gouvernance est en mouvement perpétuel (création de nouveaux produits data, suppression des anciens et transformation de l’existant). Ainsi le modèle de gouvernance doit fonctionner avec un changement continu à travers cette méthodologie, sans interrompre l'expérience des consommateurs.
Ainsi, l’utilisation du Data Mesh a besoin de s’appuyer sur les architectures distribuées et dynamique composées de plusieurs entités qui communiquent entre elles (peer-to-peer) plutôt que de dépendre d'une équipe centralisée. Cette approche permet une gestion indépendante du cycle de vie de chaque produit de données, tout en favorisant une interconnectivité et une intégration souples entre eux.
Les éléments du système de gouvernance, tels que les points de levier et la boucle de rétroaction décrits précédemment, reposent sur des mécanismes automatisés construits par la plateforme et intégrés dans l'architecture distribuée.
Gouvernance Fédérée
Le deuxième principe du concept de Data Mesh implique que chaque équipe est responsable d'un domaine spécifique. Elle définit ses propres objectifs mesurables définissant la qualité de service attendue pour son système ([SLOs](https://fr.wikipedia.org/wiki/Service-level_objectives#:~:text=Les service-level objectives (SLOs,de service et un client.) - Service-Level Objectives)* et gère ses données de manière indépendante.
Pour que tout fonctionne ensemble, il y a des règles communes pour garantir que les différents domaines puissent interagir entre eux. Le Data Mesh définit les éléments opérationnelles suivantes :
- Équipe fédérée (Federated team) : une équipe composé de Product Owner par domaine et d’experts (légal, sécurité) ;
- Guide des valeurs (Guiding values) : des valeurs qui guident la prise de décision et la gestion des produits data ;
- Normes globale (Policies) : des normes tels que des consignes de sécurité, de conformité, juridiques et d'interopérabilité et normes régissant le maillage ;
- Points de levier (I_ncentives_) : des points de levier qui équilibrent l'optimisation locale et globale.
L’Équipe fédérée
Le premier élément opérationnel, l’équipe fédérée a pour responsabilité collective de :
- Contribuer à la définition de la gouvernance qui régit les produits (les domaines) ;
- Concevoir l’expérience et prioriser les features de la plateforme et prendre en charge la gouvernance définie ;
Exemple : anonymisation des informations personnelles identifiables ****lors de l'écriture/de la lecture des données, ou mettre en œuvre des API standardisées pour accéder aux informations de découverte de chaque produit de données
- Informer et influencer la hiérarchisation et la conception des fonctionnalités de la plateforme et leur adoption par tous les domaines de données ;
- Faciliter et soutenir le process de gouvernance.
Guide des valeurs
Le deuxième éléments est le guide qui est définis et gérés collectivement par les équipes au sein de chaque domaine. Il influence les décisions et la résolution des conflits entre les équipes de gouvernance et du produit.
Certaines décisions nécessitent une norme globale pour toutes les équipes.
Règles d’accessibilité de la donnée, de sécurité ou encore de la conformité des données (Règlement Général sur la Protection des Données - RGPD)
Aussi la mise en place de règles de standardisation globales permet de faciliter l’interopérabilité du maillage (Produit Data et platform)
Enfin, dans l’organisation Data Mesh, la responsabilité des décisions et de leur exécution est déléguée aux personnes qui connaissent le mieux le problème. C’est à dire localement dans l’équipe produit, même si une décision est prise au niveau global.
La Data Quality ou l’accessibilité sont gérées par chaque équipe de domaine
Normes globale
Ces normes, gérées et définies par l’équipe fédérée, peuvent être définis par un ensemble de règles pour gérer la sécurité, l'accessibilité, la qualité et la modélisation des données
Ces règles peuvent être locales, spécifiques à chaque équipe, ou globales, s'appliquant à toutes les équipes de produits de données.
Idéalement, pour minimiser les frictions, il est préférable de limiter les règles globales et d'automatiser ces règles au niveau de la plateforme pour les rendre applicables à toutes les équipes Produit Data.
Points de levier
Concernant ce quatrième élément, il est important de souligner que le Data Mesh ne représente pas simplement un changement technologique mais plutôt une transformation organisationnelle. Un moyen pour faire face à cette transformation sont les points de levier. Cela offre deux avantages :
- Le point de levier local permet d’accélérer et d’autonomiser chaque domaine. Le point de levier global permet la construction de Produit Data interconnecté plutôt que cloisonnés ;
- Le modèle de gouvernance opérationnel doit créer, monitorer et ajuster en permanence ces points de levier locaux et globaux.
L’effet de levier nécessite une expérimentation et des itérations continues pour fonctionner.

Industrialisation du modèle de gouvernance
Ce troisième principe a pour objectif d’appliquer des politiques de gouvernance fédérée et automatisée au niveau de chaque produit.
Il existe 4 moyens possibles d’implémentation :
- Standards as Code : C’est un ensemble de règles. Pour le comportement, l’interface ou encore la structure de la donnée. Par exemple une data interface avec une API qui expose la donnée.
- Policies as Code : Il s’agit de compliance, accessibilité, sécurité, … Par exemple rendre les données RGPD accessibles de manière anonymisée afin de maintenir un état de fonctionnement pour les utilisateurs.
- Automated Tests : Mettre en place des tests automatisés, comme l'intégration continue (CI/CD), pour détecter rapidement les erreurs et les corriger dès que possible.
- Automated Monitoring : Maintenir les règles définies en mettant en place un monitoring continu. Par exemple, configurer un système de monitoring avec des vérifications de conformités sur les inficateurs de niveau de service (SLO.
En conclusion
La gouvernance du Data Mesh vise à améliorer l’approche de la gouvernance des données par l’automatisation et le traitement des données. Il s’agit d’une méthode par laquelle nous définissons et appliquons les bonnes pratiques.
Ainsi comme nous l’avons vu précédemment, le modèle de gouvernance du Data Mesh se compose de 3 piliers qui travaillent en synergie pour créer un écosystème de données agile et interconnecté, tout en décentralisant la responsabilité et en garantissant la qualité et la conformité des Produits Data.
- Le premier est le System thinking dans un écosystème interconnecté de plusieurs Produits Data et de plateforme indépendant mais pourtant avec des équipes désilotées.
- Le second applique la fédération du modèle de gouvernance. D’un point de vue social et organisationnel, cela permet de créer un alignement entre les domaines et les plateforme.
- Enfin le troisième est l’industrialisation du modèle qui permet d’embarquer les règles de gouvernance dans chaque domaine et plateforme.

Définition
Service-Level Objectives (SLO) : Les objectifs de niveau de services sont des éléments clés de l'accord de niveau de services entre un fournisseur de service et un client.
Sources pour en savoir plus :
Ces formations pourraient aussi vous intéresser
2 jours
4 à 8 personnes
Deux jours pour construire votre Personal OS PM de A à Z et décrocher la certification RS6891.
1 jour
4 à 12 participants
Comment tirer le maximum des agents de coding ? Contexte persistant, commandes sur mesure et orchestration multi-agents.
Data-dictionnaire
Stratégie IA
Data Mesh
Le Data Mesh est un paradigme d'architecture de donnees decentralise, fonde sur 4 piliers : ownership par domaine, Data as a Product, plateforme en self-service et gouvernance federee. Il est l'application du Domain-Driven Design a la data.
Data-dictionnaire
Stratégie IA
Data Governance
La Data Governance est le cadre strategique et operationnel qui definit les regles, les roles et les processus pour gerer les donnees d'une organisation de maniere fiable, securisee et conforme.
Data-dictionnaire
Produit
Data As A Product
Le Data as a Product est une approche qui consiste a traiter les donnees comme un produit a part entiere, avec un responsable, des utilisateurs et des standards de qualite. C'est l'un des 4 piliers du Data Mesh.
Ces contenus pourraient
aussi vous intéresser
Article
Stratégie IA
5 min
🌶️
Débutants
.png)
La Forward Data Conference revient en 2025 pour connecter toute la communauté Data & IA.
11.07.2025
Article
Stratégie IA
5 min
🌶️
Débutants

Pourquoi et comment nous avons créé la Forward Data Conference, conférence Data & IA à Paris.
09.07.2025
Article
Stratégie IA
5 min
🌶️
Débutants

Pourquoi tant de projets Data restent bloqués au stade du PoC sans jamais partir en production.
12.05.2025
Vidéo
Stratégie IA

Au cours de cette interview, Julien nous partagera les enseignements et convictions qu'ils ont tiré dans leur transformation vers le Data Mesh. Et nous le verrons, les challenges sont encore nombreux, car en plus que des changements technologiques, ce sont des changements de paradigmes qu'il faut opérer.La théorie du Data Mesh est belle, place maintenant au pragmatisme des retours d'expérience terrain !
08.07.2025
Vidéo
Stratégie IA

Luc est l’une des plus grandes têtes pensantes françaises de l’IA et de la technologie, et viendra répondre aux questions de Yoann Benoit lors d’une interview en live. Nous discutons de son parcours, son amour pour les maths et pour la Silicon Valley, ses multiples vies professionnelles, et nous parlons bien entendu d’Intelligence Artificielle (ou plutôt d'Intelligence Augmentée...).
08.07.2025
Vidéo
Stratégie IA

01.07.2025
Prêt à accélérer votre Transformation ?
Nos experts vous accompagnent à chaque étape de votre parcours Data & IA. Discutons ensemble de vos enjeux et objectifs.